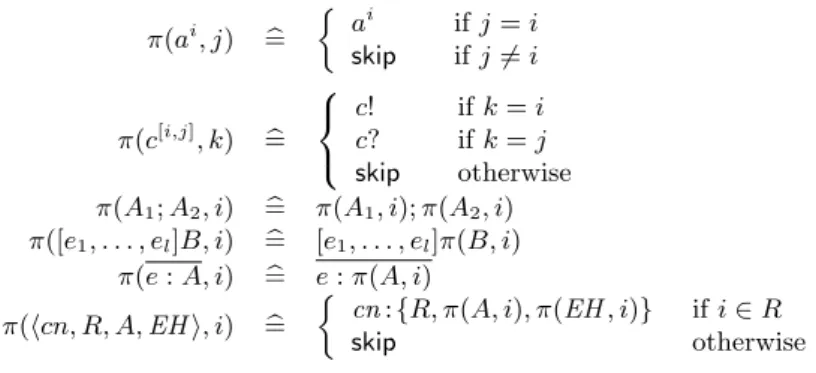GRACE TECHNICAL REPORTS
Proceedings of the Sixth Asian Workshop on
Foundations of Software
Zhenjiang HU and Jian ZHANG
(Editors)
GRACE-TR 2009–01
April 2009
CENTER FOR GLOBAL RESEARCH IN
Preface
This technical report contains the proceedings of the
Sixth Aisan Workshop
on Foundations of Software
(AWFS 2009) held in Tokyo, Japan, April 6-8,
2009, hosted by the GRACE Center of National Institute of Informatics.
The Asian Workshop on Foundations of Software (AWFS) addresses
foundational problems in current and future software design, development,
and analysis. The previous five AWFS were held in Hangzhou in 2002,
Nan-jing in 2003, Xi’an in 2004, BeiNan-jing in 2005, and Xiamen in 2007. It is our
best wish that this workshop would further stimulate various activities
lead-ing to formation of new forums for Asian researchers in the area of software
science and technology.
This year, we have three invited talks given by David Lorge Parnas, Yike
Guo, and Shinichi Honiden, nine presentations of regular papers (including
three short papers) selected from the submissions, eight short presentations
of published papers, and six short presentations of ongoing work.
On behalf of the program committee, we would like to thank
Dong-ming Wang and Tetsuo Ida, the program chairs of AWFS 2007, for their
invaluable advices on organization of AWFS 2009, the invited speakers who
agreed to give talks, all those who submitted papers, and all the referees
for their careful work in the reviewing and selection process. The support
of our sponsors is also gratefully acknowledged. In addition to the GRACE
Center of National Institute of Informatics, we are indebted to Asian
Asso-ciation for Foundation of Software (AAFS). Finally, we would like to thank
the members of the local arrangements committee, notably Yoshiko Asano,
Akimasa Morihata, Yingfei Xiong, and Yumi Yamasaki, for their invaluable
support throughout the preparation and organization of the symposium.
April 2009
Zhenjiang Hu
Workshop Organization
Workshop Chair
Tetsuo Ida
Tsukuba University, Japan
Program Chairs
Zhenjiang Hu
National Institute of Informatics, Japan
Jian Zhang
Chinese Academy of Sciences, China
Program Committee
Yiyun Chen
University of Science and Technology of China, China
Wei-Ngan Chin
National University of Singapore, Singapore
Jin Song Dong
National University of Singapore, Singapore
Yuxi Fu
Shanghai Jiaotong University, China
Qingshan Jiang
Xiamen University, China
Xuandong Li
Nanjing University, China
Shaoying Liu
Hosei University, Japan
Zhiming Liu
UNU/IIST, China
Shilong Ma
Beihang University, China
Shin-Cheng Mu
Academia Sinica, Taiwan
Yasuhiko Minamide
Tsukuba University, Japan
Mizuhito Ogawa
JAIST, Japan
Atsushi Ohori
Tohoku University, Japan
Nguyen Hua Phung
Ho Chi Minh City Univ. of Technology, Vietnam
Zongyan Qiu
Peking University, China
Masahiko Sato
Kyoto University, Japan
Zhong Shao
Yale University, USA
Masato Takeichi
University of Tokyo, Japan
Dongming Wang
Beihang University, China and UPMC-CNRS, France
Ji Wang
National University of Defense Technology, China
Yi Wang
Uppsala University, Sweden
Kwangkeun Yi
Seoul National University, Korea
Mingsheng Ying
Tsinghua University, China
Nobukazu Yoshioka
National Institute of Informatics, Japan
Taiichi Yuasa
Kyoto University, Japan
Wenhui Zhang
Chinese Academy of Sciences, China
Jianjun Zhao
Shanghai Jiaotong University, China
Local Arrangements
Yoshiko Asano
National Institute of Informatics, Japan
Akimasa Morihata
University of Tokyo, Japan
Yingfei Xiong
University of Tokyo, Japan
Table of Contents
Invited Talk I
Functional Documentation Using Tabular Expressions . . . 6
David Lorge Parnas
Session 1: Language Design and Implementation
Interfacing with C Polymorphically . . . .
Atsushi Ohori and Katsuhiro Ueno
A Global-to-Local Approach for Rigorous Development of Distributed
Systems with Coordinated Exception Handling . . . 7
Chao Cai and Zongyan Qiu
Translation and Optimization for a Core Calculus with Exceptions . . . 21
Cristina David, Cristian Gherghina, and Wei-Ngan Chin
Session 2: Software Engineering I
Concern Based Approach to Generating SCR Requirement
Specification: a Case Study . . . 23
Ying Jin, Weiping Hao, and Pengfei Ma
User-oriented Preparative Treatments for Requirements Engineering . . . 25
Fei He and Yoshiaki Fukazawa
The Specification Construction of a Service-Oriented System Using the
SOFL Method . . . 33
Weikai Miao and Shaoying Liu
Session 3: Software Engineering II
Consistency of Networks of Components . . . 46
Zhiying Liu, David Lorge Parnas, and Baltasar Trancon y
Widemann
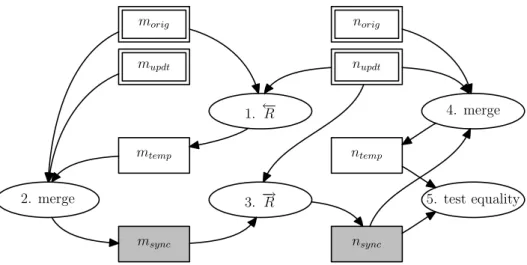
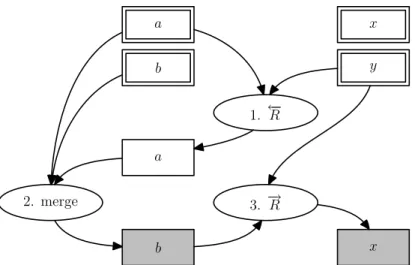
From Bidirectional Model Transformation to Model Synchronization . . . 56
Yingfei Xiong, Zhenjiang Hu, and Masato Takeichi
Bidirectionalizing Structural Recursive Transformation on Graphs . . . .
Soichiro Hidaka, Zhenjiang Hu, Hiroyuki Kato, and
Keisuke Nakano
Invited Talk II
Session 4: Languages
Linguistics as Physics . . . .
Masahiko Sato
On the Computation of Quotients and Factors of Regular Languages . . . 67
Mircea Marin and Temur Kutsia
Copy-on-Write in the PHP Language . . . 79
Akihiko Tozawa, Michiaki Tatsubori, Tamiya Onodera, and
Yasuhiko Minamide
Session 5: AOP and Program Transformation
Finding Bugs in AspectJ is not Difficult . . . 81
Haihao Shen, Sai Zhang, and Jianjun Zhao
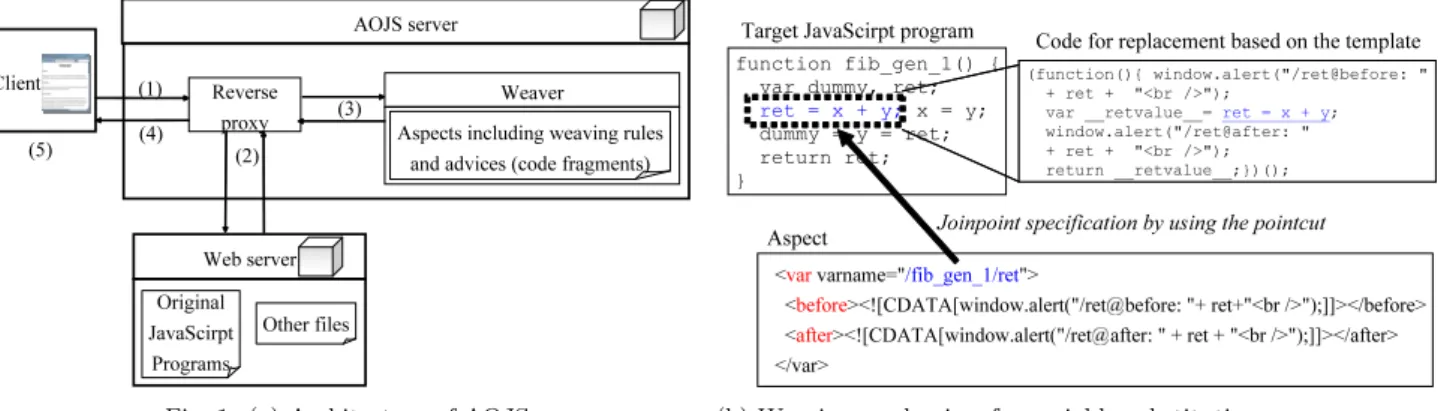
AOJS: Aspect-Oriented JavaScript Programming Framework . . . .84
Hironori Washizaki, Atsuto Kubo, Tomohiko Mizumachi,
Kazuki Eguchi, Yoshiaki Fukazawa, Nobukazu Yoshioka,
Hideyuki Kanuka, Toshihiro Kodaka, Nobuhide Sugimoto,
Yoichi Nagai, and Rieko Yamamoto
Rewriting XQuery to Avoid Redundant Expressions based on Static
Emulation of XML Store . . . .
Hiroyuki Kato, Soichiro Hidaka, Zhenjiang Hu, Yasunori
Ishihara, and Keisuke Nakano
Session 6: Logic and Formal Method
Formalization and Specification of Geometric Knowledge Objects . . . 86
Dongming Wang
A Revised Pointer Logic for Verification of Pointer Programs . . . .99
Zhaopeng Li, Yiyun Chen, Baojian Hua, and Zhifang
Wang
Combining Formal Engineering Methods and Democracy for Software
Quality Assurance . . . .
Shaoying Liu
A Dynamic Description Logic for the Three-level RBAC model . . . .117
Li Ma, Shilong Ma, Yuefei SuiYuefei Sui, Cungen Cao,
Jianghua Lv
Invited Talk III
Session 7: Language Implementation
Sharp Program Analysis and Test Data Generation . . . .
Jian Zhang
Porting GNU Compiler Collection and GNU Binary Utilities for C16X .139
Le Ton Chanh, Le Minh Vu, and Nguyen Hua Phung
Session 8: Programming Algebra
The Third Homomorphism Theorem on Trees Upward & Downward
Leads to Divide-and-Conquer . . . .149
Akimasa Morihata, Kiminori Matsuzaki, Zhenjiang Hu,
and Masato Takeichi
Functional Documentation Using Tabular
Expressions
- An Integrated Approach to the Use of
Mathematics in Computer System Design
David Lorge Parnas
Emeritus Professor McMaster UniversityCanada
Abstract
Over a period of more than 40 years, Computer Scientists have been proposing mathe-matical approaches to software development. We have seen countless papers about:
• Description and analysis of networks of hardware elements (logic design)
• Specification and verification of sequential programs.
• Specification and verification of concurrently executing programs
• Specification and description of module and component interfaces
• Description of a module or components internal design decisions
• Description/Specification of a component or modules external behaviour
• Description/Specification of a computer systems external behaviour
A Global-to-Local Approach to Rigorously Developing
Distributed System with Exception Handling
(Full version is published elsewhere. Included here for informal use only)
Chao Cai, Zongyan Qiu
LMAM and Department of Informatics, School of Math.,
Peking University, Beijing, China
E-mail: {caic, qzy}math.pku.edu.cn
Abstract
Cooperative distributed system covers a wide range of applications such as systems for industrial controlling and business-to-business trading, which are usually safety-critical. Co-ordinated exception handling (CEH) refers to exception handling in cooperative distributed system, where exceptions raised on a peer should be coped with by all relevant peers in a consistent manner. A crucial problem in using a CEH algorithm is how to develop peers which are guaranteed coherent in both normal and exceptional executions. Straightforward testing or model checking is very expensive. In this paper, we propose an effective way to develop systems with correct CEH behavior. Firstly, we formalize a CEH algorithm by proposing a Peer Process Language to precisely describe distributed systems and their operational seman-tics. Then we dig out a set of syntactic conditions, and prove its sufficiency to ensure system coherence. Finally, we propose a global-to-local approach, including a language for describing distributed systems from a global perspective and a projection algorithm, for developing the systems. Given a well-formed global description, a set of peers can be generated automat-ically. We prove the system composed by these peers satisfies the conditions, that is, it is always coherence and correct with respect to CEH.
Keywords: Distributed system, Exception Handling, Fault Tolerant, Formal Methods
1
Introduction
A cooperative distributed system involves several independent peers (subsystems) that work together to implement some global function or achieve some common goal. Many application systems fall into this category, e.g., industrial controlling system [24], patients’ embedded acces-sorial system [5], railway scheduler [2], and business-to-business trading system. Many of these systems are safety-critical, which may cause risks for human lives or great financial losses if not fault-tolerant. Thus, it is crucial to guarantee that they provide intended behavior even when some faults or errors occur in execution.
To achieve fault-tolerance, exception handling (EH) mechanism is often used as a recovery-layer. With EH support, any perceptible fault or error are converted to some exception. The language or platform offers a kind of control structures that allows programmers to describe the replacement of the normal execution when exceptions occur. Most modern programming languages include EH mechanism as a fundamental feature, for easily describing the application-specific logic of the recovery procedures.
Although the EH mechanism for sequential programs is relative mature, it is not the case for the distributed systems. Due to the decentralization and cooperation features, in considering the exception handling here, we will inevitably meet two fundamental new problems: coordinated exception handling andconcurrent exceptions.
propagated to all relevant peers so that they can work collaboratively for returning the whole system to a consistent state [4, 1]. Various reasons call for attention onconcurrent exceptions in CEH. Because peers in a system run parallelly and independently, two or more exceptions may occur on different peers “simultaneously”. A typical situation is when a peer meets an exception and notifies its partners for this, some partners may encounter other exception(s) before receiving the message. For the coordinated handling to be possible, those situations should be integrated into the cooperation model.
Randell and Xu et al [4, 22] developed an algorithm for exception handling in cooperative distributed systems, based on the concept of “Coordinated Atomic” (CA) actions. The algorithm copes with both problems mentioned above. However, the algorithm was informal described . To introduce a linguistic mechanism is an important future work announced in [22]. One motivation of the work presented here is to make the algorithm clearly defined and easy-usable.
A crucial problem in using the CEH algorithms is how to develop peers which are guaranteed coherent in both normal and exceptional execution. On the one hand, a composed system con-sists of a set of cooperative peers, where each peer participates several CAs and may encounter exceptions anywhere in the execution. On the other hand, exceptions may be propagated in two directions: either horizontally to other peers working in the same CA, or vertically to the enclos-ing CA. Both situations make it very difficult to guarantee the system coherency. Straightforward testing or model checking is very expensive. As shown in [21], checking a manufacture controlling system generates 1034states, and costs more than a week. As another motivation of our work, we want to develop a new approach not only to rigorously develop distributed system with exception handling, but also to provide effective static verification.
The first contribution we made is the definition of a Peer Process Language (PPL), by which we can formally define peers and the composed systems. We give an operational semantics for PPL, and embed the CEH algorithm in the semantics.
The second contribution is that we give a set of syntactic conditions for a group of peers with nestedscopes (the term we used for CA) to form a system with coherent behavior, and prove the sufficiency of the conditions based on the operational semantics.
However, the syntactic conditions are not convenient enough for developers. To check a com-posed system, we must compare all its peers pairwisely. As the most important contribution of the paper, we propose a global-to-local design approach to facilitate system designers, inspired by the idea of Web service choreography.
Our global-to-local approach suggests a three steps development: write a global specification, validate it, and finally project it into a set of peer specification. We define a Global Protocol Lan-guage (GPL) for the description of the global protocols, and a projection algorithm for automatic generating the specification for each peer. The approach is superior in several aspects: the global specification is easier to write; the conditions for well-behaved systems become much simpler on the global level. The automatically generated peers, putting together, will show the intended behavior described by the protocol. The system they composed will never deadlock w.r.t. CEH.
We implement the CEH framework formally defined here. A Java demonstration will be discussed in the paper with some primitive recognition.
The rest of the paper is organized as follows. Section 2 devotes to language PPL and some relative concepts. The CEH algorithm is introduced informally in Section 3, and the conditions and properties for consistent systems are given in Section 4. The protocol language with a projection algorithm is given in Section 5. Then we formalize PPL and CEH in Section 6, with proofs for the sufficiency of conditions in Section 7. As a demonstration of CEH, we show an implementation of CEH for threads in Java in Section 8. Finally, related work and conclusion are given.
2
A Peer Language
A : : = skip (skip)
| BA (basics)
| [e1, . . . , el]BA (ex-decl.)
| A;A (sequential)
| sn:{R, A,EH} (scope)
EH : : = e:A
BA : : = a (local act.)
| c! (send) | c? (receive) Figure 1: Syntax of PPL
It is a formal language containing features such as pre/post conditions. Issarny [11] proposed an object-oriented language supporting CEH. The language is rich with many details, e.g., arithmetic expression and procedure definition. For easily understanding and formal proving, we define a small language as an extension of CSP [10], to capture the kernel of a peer with respect to CEH.
The language PPL is built on three fundamental concepts.
• Peer. A distributed system consists of several peers (independent subsystems) which com-municate with one another.
• Exception interface. Each activity performed by a peer may either complete successfully, or fail and cause an exception. So each activity should be annotated by all the potential exceptions it may cause.
• Exception block. Programs are structured as blocks to confine exception [8]. Just like EH in common programming languages, an exception block contains a normal activity and a group of exception handlers. In addition, each block contains a list of names of the peers involved.
The syntax of PPL is given in Figure 1. HereAdenotes an activity. BAis the basic activity which is either a local one or a communication. A local activity abstracts some real computations done by a peer. We will usea, a1, . . .to denote local activities, and use c!,c? for the sending and receiving through channelc. The exception declaration [e1, . . . , el]BAmeans that the execution of
BAmay fail and cause one of the declared exceptions. A scope is an exception block, which has a namesn and a body consisting of three components: Ris a name-set of the participating peers; A is the normal activity and EH is exception handlers. Conceptually, EH is a finite function from exception names to recovery activities, if EH = e1 : A1, ..., el : Al, then EH(ei) = Ai,
(i ∈ {1, ..., l}). For scope sc, we usesc.Name, sc.R, sc.A and sc.EH to denote its name, set of participating peers’ names, normal activity and exception handlers respectively.
Definition 1. A peer is defined as a pair, (r, sc), where r is name and sc is behavior. The behavior is a scope. We will useα, α1 for peer definitions, and r, r1 for peer names. We will use α.Nameandα.SCto denote name and behavior ofα.
Definition 2. AComposed System(simply, a system) consists of several peers. We will denoted it as{α1, . . . , αn}.
By scanning a system, we can build up acontext
Γ :R→SNames→Scopes
HereRis the set of peer names in the system,SNamesthe set of scope names, andScopesthe set of scopes. Γ(r)(sn) is the definition of scope namedsn in peerr.
3
CEH Algorithm: Informal Description
N
T1: ex/ex! or
ex?/ex!,k--T7: ok! T10:
ex?/k--C
T3: k=0
T9:k=0
T6:
T8:
ok?/k--T4: ex EH T0: /k:=n
EF
T2: (ex? or
ok?)/k--F
E
T5:
Figure 2: State Graph
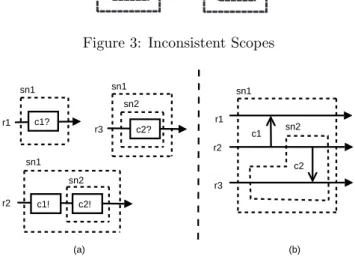
In a distributed system, each peer will execute a series of activities encapsulated in a hierarchy of scopes. In the execution of a scope, a peer may be in one of six states, as depicted in Figure 2, where Nis the normal state. To facilitate a two-step commitment, Cand Fare used to denote complete and finish states respectively. Other states are special for CEH, whereEmeans the peer or its partners encounter some exceptions,EHmeans the peer is handling an exception, andEF means that the peer fails to handle an exception.
Figure 2 is the state transition graph of a peer in a scope with respect to CEH. Here T1, T2, ... are labels of transitions, k is a counter. The transitions are marked with “event/activity” pairs. The eventex indicates the peer encounters an exception. Moreover, ex? andex! stand for receiving and sending an exception notification,ok? andok! stand for receiving and sending a complete notification, respectively. For example,T6:ok?/k--means when receiving a complete notification, the peer decreaseskand does the transition.
Initially, a peer begins a scope at stateNand sets the counterkas the number of partners in the scope (T0). If an exception occurs or an exception notification is received, the peer stops its normal flow, jumps toEand informs all partners (T1). To work collaboratively, the peer can not start its handling before it knows that all peers in the same scope have entered stateE(thus,k= 0). When the peer receives a notification from some partner, the counter decreases (T2). Whenk
becomes zero, the peer calls anexception resolutionalgorithm to determine an exception to handle (T3). If an exception occurs in a handler, the scope is aborted and the exception propagates to the outer scope (T4toEF). Otherwise, if the handling ends normally, the peer exits the scope (T5).
On the other hand, if a peer completes the execution in a scope, it employs a two-step com-mitment. Firstly, it sends a complete notification to all partners and turns to stateC(T7). Then, it waits there for the messages from its partners. If any partner encounters an exception, the peer jumps toE(T10) and acts as what is stated above. Otherwise, each partner will send a complete notification to the peer (thus,k= 0), it turns toFand finishes the scope (T9).
In transitionT3, we need an algorithm for the peers to determine one exception to handle when some exceptions happened. Many strategies can be adopted here, e.g., [4] organized all exceptions into a tree and handled the minimal common ancestor when multiple exceptions detected, [20] suggested a complete order for peers. The lexical order of handlers in a scope can also be used here. Other considerations are possible. In the formal definition in Section 6, we wrap the strategy into a function and leave it to the implementation.
sn1
r1 r2
sn2
sn2 sn1
Figure 3: Inconsistent Scopes
r3 sn1
sn2
c2?
r1
sn2
r3 r2
sn1
c1
c2 r1
sn1
c1?
r2 sn1
sn2
c2! c1!
(a) (b)
Figure 4: Consistent Scopes
execution, a peer will go through a set of nested scopes. Before a peer enters a nested scope, it will push the all the information of current scope, including its state, the uncompleted activities and the counterk, into a stack. Once the peer successfully finishes the nested scope, it pops the stack and resumes the execution of this scope. When executing a nested scope, the peer may encounter an exception while handling another exception; also it may receive an exception notification from a partner in an outer scope. In both situations, the peer will abort the nested scope and handle the exception in an outer one.
We will formalize the algorithm by detailed transition rules in Section 6.
4
Correctness and Consistent Conditions
Now we consider the correctness of the algorithm. Intuitively, for a composed system, we want all peers to be coherent in both normal and exception situations. Basically, the following requirements should be satisfied.
REQ-1. If no peer encounters an exception, all scopes will be completed normally.
REQ-2. If a peer encounters an exception in a scope, all peers involved in the same scope will stop normal execution and go to handle a same exception.
REQ-3. A system is deadlock-free with respect to the CEH procedures.
These requirements seem simple, but not any set of peers can form such a coherent system. For example, the two peers depicted in Figure 3 can not work cooperatively. Even if the two peers are lucky to avoid all exceptions and complete all normal activities of the inner scopes. Then,r1 will notifyr2 and wait forr2 to completesn2. At the same time, r2 will wait forr1 to complete sn1, and thus they fall into deadlock.
4.1
System Consistency
isCo(P, Q) =
true ifP =skip∨P =²
isCo(P′, Q) ifP =ba;P′,bais a basic activity isCo(P′, Q) ifP =sc;P′∧sc.Name6∈SN(Q) isCo(P′, Q′) ifP =sc1;P′∧Q=sc2;Q′
∧sc1 is scope-consistent withsc2 f alse ifP =sc1;P′∧Q=sc2;Q′
∧sc1.Name∈SN(Q)∧sc2.Name∈SN(P)
∧sc1 is not scope-consistent withsc2 isCo(Q, P) otherwise
Figure 5: Consistent Activity
where all peers can be merged into a global graph, depicted as Figure 4 (b), where neither any two scopes overlap, nor any message goes across the boundary of scopes. In the following of this subsection, we will propose some syntactical conditions to capture these intuitions. To focus on CEH, we assume the execution of normal sending, receiving and local activities will always terminate, either normally or exceptionally. Then the conditions can be given as a definition for consistent system.
Definition 3. We say system{α1, . . . , αn} is consistent, if the following conditions hold.
• Any two scopes appearing in same peer must have different names.
• if one scope (sn1:{R1, A1,EH1}) is nested in the other (sn2:{R2, A2,EH2}), i.e., it is in A2 or EH2, thenR1⊆R2.
• handlers in the outmost scope for each peer intend to perform a last-wish recovery, i.e., no exception will be thrown any more.
• For any αi, αj ∈ {α1, . . . , αn},αi.SCis “scope-consistent” withαj.SC. The concept
“scope-consistent” is defined below.
Definition 4 (Scope-Consistent). Scopes sc1 and sc2 are consistent, if sc1.Name=sc2.Name∧ sc1.R=sc2.R, furthermore, sc1.Aand sc2.A, sc1.EHand sc2.EHare consistent respectively.
Exception handers eh1 andeh2 are consistent, ifdomeh1=domeh2, andeh1(e)is consistent witheh2(e)for each e∈domeh1.
ActivitiesP andQare consistent, if each pair of scopes with the same name appearing both in P andQare consistent, and these scopes have the same relative order and nest structures. ¤
In other words, two activities P and Q are scope-consistent, if isCo(P, Q) = true, where functionisCo() is defined in Figure 5, andSN(P) denotes the set of scope names appeared inP.
The system shown in Figure 4 (a) is consistent, which can be merged into a global picture (b) without intersectant scopes. In PPL, the peers are:
α1= (r1,sn1:{R1, c1?, ²})
α2= (r2,sn1:{R1, c1!;sn2:{R2, c2!, ²}, ²}) α3= (r3,sn1:{R1,sn2:{R2, c2?, ²}, ²})
whereR1={r1, r2, r3}, R2={r2, r3}.
4.2
Properties of consistent systems
We say a peerrterminates scopesc if it is either in scopescand its state isF, or it has exited fromsc. We say a scopesc terminates if all its participating peers terminate the scope.
For the consistent systems, we propose several propositions and a theorem here.
Proposition 1. corresponding [REQ-1] In a consistent system, supposing all relative peers have entered scope sn, if no peer will encounter any exception, then scope sn will terminate.
Proposition 2. corresponding [REQ-2]Suppose one or more exceptions happen in scope sn, if all relative peers have entered sn and no exception happens in outer scopes, these peers will enter stateE, and determine an identical exception to handle.
Proposition 3. Suppose all relative peers have entered sn, and all its inner scopes will terminate, if some exceptions happen, either in sn, or its outer scopes, or in inner scopes and propagate to sn, then sn will terminate.
Theorem 1. corresponding [REQ-3]A consistentsystem will never deadlock.
These propositions and theorem will be formally proved in Section 7 based on an operational semantics of PPL defined there.
Having the properties, we can determine whether a system is coherency by checking its peers according to the conditions given in previous subsection. For these complicated conditions, the checking would not be an easy job. To make the system developing easier, we will present a design approach for consistent systems in the next section. The design approach enables us to specify the system as a whole, and then generate the specification (with all scope structures) of each peer automatically.
5
Global-to-Local: Design and Implementation
It is not easy to develop a set of peers to form a consistent system, due to the complex consistent conditions (Section 4). The situation is even worse if the peers are developed by independent organizations for business applications. To overcome this difficulty, we propose a global-to-local development methodology, where a protocol is specified from a global viewpoint, then is used to generate the peers which will always make up a consistent system. For this, we define in section a protocol language GPL (for Global Protocol Language), then propose a projection to generate peers in PPL from GPL specifications. The validation conditions are also discussed.
5.1
Protocol Language
GPL is designed for writing global scenario (protocols) of several peers by specifying their col-laborative observable behavior in both normal execution and exception handling. GPL allows sub-protocols to be nested in any depth:
C : : = hcn, R, A,EHi EH : : = e:A
BA : : = ai | c[i,j] i6=j A : : = BA | [e1, . . . , el]BA
| C | A;A
A GPL protocol takes a similar form as a activity in PPL, except communications.
A protocol C consists of a name cn, a peer-name-set R, an activity A and some exception handlers EH. A basic activity BA is either a local one ai, where i indicates that its performer
is peer ri, or a communication c[i,j] from ri to rj. An activityA can be a basic, perhaps with
exception declaration, a sub-protocol, or a sequential composition. The exception declaration is similar to that in PPL, whilec[i,j]with exception declaration means the exceptions may be raised inri or rj during the communication.
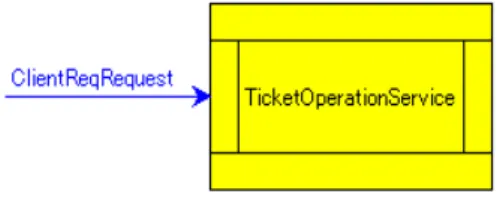
π(ai, j) b
=
ai ifj=i
skip ifj6=i
π(c[i,j], k) =b
8 < :
c! ifk=i c? ifk=j
skip otherwise
π(A1;A2, i) =b π(A1, i);π(A2, i)
π([e1, . . . , el]B, i) =b [e1, . . . , el]π(B, i) π(e:A, i) =b e:π(A, i)
π(hcn, R, A,EHi, i) =b
cn:{R, π(A, i), π(EH, i)} ifi∈R
skip otherwise
Figure 6: Natural Projection
Definition 5. A protocol is well-formed, if the protocol and all sub-protocols have different names, each performer of the activities and handlers of a protocol are declared in its peer-name-set, and each protocol’s peer-name-set is a subset of its containing protocol’s.
5.2
Projection and Implementation
A protocol describes collective behaviors of a group of peers from a global viewpoint. However, protocols are not executable, their behavior should be implemented by cooperative peers. In this subsection, we propose a projection algorithm for extracting the behavior description of each peer from global protocols. Figure 6 defines a simple projection, which partitions a protocol to produce the designated peer following its structure. We name it thenatural projection.
With the projection, we can generate a composed system from a protocol. Suppose C is a protocol withnpeers (|C.R|=n). We define
π(C) =b {(C.R(i), π(C, i))|i∈1..n}
whereC.R(i) is the name of theith peer in C. We callπ(C) the composed system defined byC. For a well-formed protocolC, systemπ(C) satisfies all consistent conditions given in Section 4. Thus we have:
Theorem 2. IfC is a well-formed protocol, π(C)is a consistent composed system.
Corollary 1. If C is a well-formed protocol, π(C)is deadlock free w.r.t. CEH.
Further connection between PPL and GPL can be investigated if semantics for both languages are given. Under some conditions, C and π(C) are behavioral equal in some sense. Interested reader can refer to our previous work [13].
Now we have a global-to-local approach to design composed systems with CEH facility, which can be summarized as follow steps:
1. Identify peers taking part in the work, and specify their collective behavior, either in normal case or in the exception case from a global view point with GPL.
2. Check whether the global specification is a well-formed protocol.
3. Project the global specification to a set of peer specifications, and fill in the details for the local activities.
[Basic Cases]
r:hσ,sn, s,skip, ǫ, θi −→r:hσ,sn, s, ǫ, ǫ, θi r:hσ,sn, s, a, ǫ, θi−→a r:hσ,sn, s, ǫ, ǫ, θi r:hσ,sn, s,[e1, . . . , el]A, ǫ, θi
−→r:hσ,sn, s, A, ǫ, θi
[N→E]
r:hσ,sn,N,[e1, . . . , el]A, ǫ, θi
−→r:hσ,sn,E,notify(ei), ǫ, θi i∈1..l r:hσ,sn,N, A,(e,sn, r′)a
ω, θi
−→r:hσ,sn,E,notify(e), ω, θ⊕ {r′7→e}i
[∗ → ∗]
r:hσ,sn, s, A,(C,sn, r′)a
ω, θi −→r:hσ,sn, s, A, ω, θ⊕ {r′ 7→C}i
[N→C]
r:hσ,sn,N, ǫ, ǫ, θi
−→r:hσ,sn,N,notify(C), ǫ, θi
[E,C→E]
s=E∨s=C
r:hσ,sn, s, A,(e,sn, r′)a
ω, θi −→r:hσ,sn,E, A, ω, θ⊕ {r′7→e}i
[E→EH]
N∈/ranθ r:hσ,sn,E, ǫ, ω, θi −→
r:hσ,sn,EH,handlerΓ(r,sn, θ), ω,domθ× {N}}i [C,EH→F]
s=EH∨(s=C∧ranθ={C})
r:hσ,sn, s, ǫ, ǫ, θi −→r:hσ,sn,F, ǫ, ǫ, θi
[Scope switch]
r:hσ,sn, s,sn′:{R′, A′, EH′};A, ǫ, θi
−→r:hsn: (s, A, θ)a
σ,sn′,
N, A′, ǫ, R′×{ N}i r:hsn′: (s′, A′, θ′)a
σ,sn,F, ǫ, ǫ, θi −→r:hσ,sn′, s′, A′, ǫ, θ′i
r:hsn′: (s′, A′, θ′)a
σ,sn,EH,[e1, . . . , el]A, ǫ, θi −→r:hσ,sn′,E,notify(e
i), ǫ, θ′i i∈1..l [∗ →EF]
sn0∈domσ ∨ sn0=sn′
r:hsn′: (s′, A′, θ′)a
σ,sn, s, A,(e,sn0, ri)aω, θi
−→r:hσ,sn′, s′, A′,(e,sn
0, ri)aω′, θ′i [Sequential]
r:hσ,sn, s1, A1, ω, θi
t
−→r:hσ,sn, s2, A′1, ω′, θ′i
r:hσ,sn, s1, A1;A2, ω, θi
t
−→r:hσ,sn, s2, A′1;A2, ω′, θ′i
Figure 7: Local Transition Rules
6
Semantics of PPL with CEH
To prove the propositions and theorems listed above, we formalize the CEH algorithm by a formal operational semantics. Firstly, we define configuration of a single peer and a system, then give transition rules for configurations.
6.1
Configurations
A peer may enter a series of nested scopes. A configuration of a peer is a tuple:
r:hσ,sn, s, A, ω, θi
whereris the peer’s name,snis the name of scope that the peer is executing,sis a state as we have in Figure 2,Ais the upcoming activity the peer will do. σa stack recording the states of all scopes where the peer has entered but not exited yet except current one. Message queueω has elements of the form (m,sn′, r′), which means peerr′ sends messagemfrom scopesn′. Tableθrecords the
states of all partners in scopesn, which is a mapping Γ(r)(sn).R→ {N,C}∪{e|e is an exception}. We will use²to represent something (stack, queue, or set) empty.
For a peer defined as (r,sn:{R, A, EH}), its initial configuration is:
r:h²,sn,N, A, ², R× {N}i
This means that the peer is in the normal state initially (represented byN), with its activityA, and all its partners in this scope are in normal state (represented by mapR× {N}).
The global configuration of a system consists of configurations of all its peers:
G={f1, . . . ,fn}
It is the initial configuration if eachfiis the initial configuration of peerri.
6.2
Local Transition Rules
Transition rules for a peer locally are given in Figure 7. A rule is in the form off −→t f′, wheref
andf′ are configurations,t an observable event. Whentis null, we simply omit it. The rules are
[Local]
fi t
−→fi′ i∈1..n {. . . ,fi, . . .}
t
−→ {. . . ,fi′, . . .} [Communication]
∃i, j∈1..n• fi=ri:hσi,sn, si, c!;Ai, ǫ, θiiandfj=rj:hσj,sn, sj, c?;Aj, ǫ, θji {. . . ,fi, . . . ,fj, . . .}
c
−→ {. . . , ri:hσi,sn, si, Ai, ǫ, θii, . . . , rj:hσj,sn, sj, Aj, ǫ, θji, . . .}
[Complete notification]
sni=snj {. . . , ri:hσ
i,sni, si, Ai, ωi, θii, . . . , rj:hσj,snj,N,send(ri,C);Aj, ωj, θji. . .} −→ {. . . , ri:hσ
i,sni, si, Ai, ωia(C,snj, rj), θii, . . . , rj:hσj,snj,C, Aj, ωj, θj⊕ {rj7→C}i. . .} [Exception notification]
snj∈domσi∨snj=sni {. . . , ri:hσ
i,sni, si, Ai, ωi, θii, . . . , rj:hσj,snj, E,send(ri, e);Aj, ωj, θji. . .} −→ {. . . , ri:hσ
i,sni, si, Ai, ωia(e,snj, rj), θii, . . . , rj:hσj,snj, E, Aj, ωj, θj⊕ {rj7→e}i. . .} Figure 8: Global Transition Rules
[Basic Cases] A peer can execute a local activity when its message queue is empty. The execution may success or cause an exception if it has declared any one. If an exception appears, the peer will enter stateE, as the the rule below.
[N→E] A peer may cause an exception if the executed activity declares some exception, and also it may receives an exception notification. Then, it will turn toE, record its partner’s state, and notify its partners bynotify. The rule of notify is described in the relative global rule below. Here⊕denotes overriding.
[∗ → ∗] No matter in which state, when receiving a completion notification, a peer records it. [N→C] When finishing normal execution, the peer notifies its partners by notify(C).
[E,C→E] When receiving an exception notification in stateE/C, the peer updates its state table and turns toE.
[E→EH] When a peer is in stateE, and all its partners have exited normal state, thus, the state table contains no “N”, the peer begins to handle exception. Here handlerΓ is a function taking a peer name r, a scope namesn, and a state table θ as parameters. It determines an exception and finds the handler for it. We wrap the resolution strategy into a function resolve and leave it to the practice.
handlerΓ(r,sn, θ)= Γ(b r)(sn).EH(resolve(θ))
[C,EH→F] If a peer knows all partners of its current scope complete, or it finishes exception handling without any fault, it can exit current scope safely (ref. rule [Scope switch]). [Scope Switch] If a peer meets a new scope, or finishes its work in a scope, it switches in/out
the scope. HereR× {N}means that all peers are in state N. If an exception happens or is re-thrown in a handler, it is propagated to the enclosing scope.
[∗ →EF] If an exception notification from outer scope arrives, the peer aborts immediately current scope, deletes messages of current scope. The premise means sn0 is an outer scope of r’s current scope (namedsn). Hereω′is the message queue obtained by filtering out all messages
of form (-,sn,-) fromω.
6.3
Global Transitions
Some local rules transit to a configuration with a call notify(m) to send m to all partners in the same scope, wherem is Cor some e. Without careful management, asynchronous approach may induce deadlocks. A scenario is given in our report [3]. Here we realizenotify(m) by a group of synchronous sending, wheresend(ri, m) sendsmtori. An invocationnotify(m) in scopesnby
ris equal to “send(r1, m);. . .;send(rk, m)”, where{r1, . . . , rk}= Γ(r)(sn).R− {r}. It was better
if we had parallel construction to implement it as “send(r1, m)k. . .ksend(rk, m)”.
In rule[Complete notification], peerrj sends a complete message to partnersriinsn jthat
is recorded in message queue. The premise asks the sender and receiver in the same scope. Rule [Exception notification]is similar, except the requirement forri is looser. Here sn
j ∈domσi
means thatri has entered the scopesn
j but not left.
7
Proofs for Theorem 1
Properties of consistent systems have been listed in Subsection 4.2. Now we given the skeleton of the proof for Theorem 1 based on the formalization above. Firstly, some lemmas.
Lemma 1. A peer can exit a scope if one of the following situations occurs: 1. Its state table is full ofC;
2. Some exceptions occurred in some outer scopes;
3. The peer finishes its exception handling, or encounters an exception when handling exception.
By Lemma 1, we can prove Theorem 1 in two steps, in the first, prove all peers can cooperatively exit a scope in each case of Lemma 1, and then apply structure induction on hierarchies of scopes.
Lemma 2. If peer r participates in scopes sn1 and sn2, and sn2 is in sn1, then for any r’s configurationr:hσ,sn, s, A, ω, θi, if sn =sn2, then, sn1∈dom(σ).
We define a partial relationpreceding for scopes.
Definition 6. We say sn1 is preceding of sn2, if there exists a peer r with sc1 = Γ(r)(sn1), sc2= Γ(r)(sn2), and sc1 appears before sc2 syntactically.
Lemma 3. If all relative peers have entered scope sc, an attempt to notify(C)or notify(e)in sc will always succeed if no exception happen in outer scopes.
Lemma 4(Deadlock-Free). A peer can always consume its message queue.
Lemma 5. If all peers have entered their exception handlers for a same exceptionein scope sn, suppose all inner scopes can always terminate and no exception will happen in outer scopes, they will finish recovery and terminate sn.
Lemma 6. If scopes sn1, ...,snl have a common direct enclosing scope, then they can be sorted
to a sequence sn′
1, ...,sn′l such that for any 1 ≤i < j ≤l, sn′j is not preceding of sn′i, and sn′j
must appear inΓ(r)(sn′
i).Afor some r if sn′i appears inΓ(r)(sn′j).A, i.e., all scopes in exception
handlers are sorted after those in normal activities.
Lemma 7. For a scope sn′ and its direct-enclosed scope sn, suppose all peers related to sn have entered sn′, all scopes preceding sn are finished, and one peer has entered sn, then the rest peers will enter sn eventually, unless exceptions happen in some enclosing scopes (include sn′).
Theorem 3. In a consistent system, suppose all relative peers enter a scope, this scope will always terminate.
From all the lemmas and propositions given above, we can easily have Theorem 1.
Proof for Theorem 1. For aconsistent system{α1, ..., αn}, we knowαj.SC.R={αi.Name|i∈
{1, .., n}}, suppose αj.SC.Nameis sn, the consistent condition ensures that all peers required by
snwill enter it. By Theorem 3, the system will always terminate.
8
Experiment
The operational semantics given in Section 6 is easy to implement. As a demonstration, we developed a Java framework where threads can handle exceptions cooperatively.
We define classes GlobalException and Peer, where Peer extends java.lang.Thread, which has attributes for the stack, state table, message queue, and methods such asenterScope(String name), waitToExitScope(),inforAllException(GlobalException ge), inforAllComplete(). Methodrun() imple-ments a hierarchy of scopes, in which each scope is a try-catch block with special form, where the first statement is always a method call of enterScope(), and the last is waitToExitScope(). Fur-thermore, non-global exceptions must be handled in the scope, but global exceptions are thrown to outer scopes.
The implementation can be revised for distributed applications, where several methods should be promoted to communicate with remote objects. Also, the CEH mechanism can be implemented on the JVM level to write eleganter codes, by applying the approach proposed in paper [23] which revises the exception mechanism for the new feature “Future” in Java 5.0.
9
Related work
Exception handling (EH) has become indispensable ingredient in programming languages and system development fields incrementally after Goodenough’s seminal work on structural EH [8]. Randell presented in [14] the rationale behind a method for structuring complex computing sys-tems by the use of “recovery blocks” and “conversations”. In [4], Campbell and Randell proposed techniques for structuring forward error recovery method in asynchronous systems. In [15] , Ro-manovsky developed a new atomic action scheme that did not impose any peer synchronization on action exit. Xuet al. [20, 19] presented a scheme for coordinated error recovery between multiple interacting objects in concurrent OO systems, and developed a conceptual model and algorithm es-pecially for distributed object systems. However, all these works are presented informally. Neither the well-formedness condition nor semantics is presented.
There have been some effort to design a language to support the concept of CA. COALA [18] is aimed to design CA actions. It is a formal language containing features such as pre/post conditions. Issarny [1] proposed a languageε
CSP to support EH in concurrent systems. A framework for EH in parallel OO language is proposed in [11], where a system is a group of recoverable actions. Each action involves several peers and a special “coordinator” works as a control center to decide whether the action fails and directs the others to handle an exception. Issarny [11] proposed an OO language supporting CEH. The language is rich with many details, i.e. arithmetic expression and procedure calling. However, these models are unsuitable for the decentralized systems, because it is hard to find a reliable peer with overwhelming power. A survey about exception handling models developed for concurrent object systems can be found in [16].
Current research trends in EH is outlined in [12], including EH in human-centered systems such as workflow. Hagen and Alonso [9] presented a solution for implementing reliable workflow processes by using EH. Romanovskyet al. [17] proposed coordinated forward error recovery for composite Web services, and defined the notion of Web Services Composition Action (WSCA), which allows constructing composite Web services in terms of dependable actions.
A framework to verify CEH is presented in [7], where a system is modeled by specification language like Alloy and B, and programmers can write and check properties using a constraint solver. In the paper, three requirements commonly for systems are enumerated as examples. But the paper does not aim to give a sufficient condition for the well-behaved systems.
10
Conclusion
The coordinated exception handling (CEH) in distributed system is very complex due to the autonomous nature of the peers in the system. Current develop methods and languages almost consider from the perspective of a local peer. It is difficult to guarantee the composition of peers can cooperate properly. Based on this recognition, we present in this paper a global-to-local approach for building the composed system consisted of multiple independent peers which supports CEH. The contributions of this work can be summarized as follows:
• Propose a group of accurate syntactic conditions for a set of peers to form a well-behaved system.
• Present an efficient global-to-local design and implementation approach for cooperative sys-tems with CEH.
• Formally define the CEH procedure by a set of operational rules, and formally proved these conditions are sufficient based on the operational semantics.
The PPL language used in our formalization can be seen as a try to introduce linguistic mech-anism for specifying nested CA actions in distributed environment. With this formal framework, we have developed a demonstrative framework, which enable Java threads to handle exceptions cooperatively. We also have a tool to automatically generate skeletons of threads, with integrated CEH in each of the thread’s code.
As a future work, it is meaningful to study the integration of CEH into existing Web services languages such as WS-BPEL and WS-CDL. Actually, Carbone et al. [6] has recognized that exception are indispensable for managing many real application situations. They identified that one missing thing in WS-CDL would be the ability of handling exceptions locally, with a standard local scoping rule. Therefore, it deserves further effort based on current formalization of CEH.
References
[1] Jean-Pierre Banˆatre and Val´erie Issarny. Exception handling in communication sequential processes. Technical Report 660, INRIA-Rennes, IRISA, 1992.
[2] D. M. Beder, A. Romanovsky, B. Randell, C. R. Snow, and R. J. Stroud. An application of fault tolerance patterns and coordinated atomic actions to a problem in railway scheduling. SIGOPS Oper. Syst. Rev., 34(4):21–31, October 2000.
[3] Chao Cai, Zongyan Qiu, Hongli Yang, and Xiangpeng Zhao. Coordinated exception han-dling in web service. Technical report, 2007. Available as Prepring 2007-23 of Institute of Mathematics, Peking University, at: http://www.math.pku.edu.cn:8000/en/preindex.php.
[4] Roy H. Campbell and Brian Randell. Error recovery in asynchronous systems. IEEE Trans. Softw. Eng., 12(8):811–826, August 1986.
[5] Alfredo Capozucca, Nicolas Guelfi, and Patrizio Pelliccione. The fault-tolerant insulin pump therapy. In Michael Butler, Cliff B. Jones, Alexander Romanovsky, and Elena Troubitsyna, editors, RODIN Book, volume 4157 of Lecture Notes in Computer Science, pages 59–79. Springer, 2006.
[6] M. Carbone, K. Honda, N. Yoshida, R. Milner, G. Brown, and S. Ross-Talbot. A theoret-ical basis of communication-centred concurrent programming. Techntheoret-ical report, To be pub-lished by W3C., 2006. Available at http://www.dcs.qmul.ac.uk/~carbonem/cdlpaper/ workingnote.pdf.
[8] John B. Goodenough. Exception handling: issues and a proposed notation.Communications of ACM, 18(12):683–696, December 1975.
[9] Claus Hagen and Gustavo Alonso. Exception handling in workflow management systems. IEEE Trans. Softw. Eng., 26(10):943–958, 2000.
[10] C. A. R. Hoare. Communicating Sequential Processes. Prentice Hall, 1985.
[11] Val´erie Issarny. Concurrent exception handling. In Proceedings of Advances in Exception Handling Techniques, LNCS 2022, pages 111–127. Springer, 2001.
[12] Dewayne E. Perry, Alexander Romanovsky, and Anand Tripathi. Current trends in exception handling. IEEE Trans. Softw. Eng., 26(9):817–819, 2000.
[13] Zongyan Qiu, Xiangpeng Zhao, Chao Cai, and Hongli Yang. Towards the theoretical foun-dation of choreography. InProc. of WWW 2007, Banff, Canada. ACM, 2007.
[14] B. Randell. System structure for software fault tolerance. IEEE Trans. on Soft. Eng., SE-1(2):220–232, 1975.
[15] Alexander Romanovsky. Looking ahead in atomic actions with exception handling. InReliable Distributed Systems, 2001. Proceedings. 20th IEEE Symposium on, 2001.
[16] Alexander Romanovsky and J¨org Kienzle. Action-oriented exception handling in cooperative and competitive concurrent object-oriented systems. InProceedings of Advances in Exception Handling Techniques, LNCS 2022, pages 147–164. Springer, 2001.
[17] Ferda Tartanoglu, Val´erie Issarny, Alexander B. Romanovsky, and Nicole L´evy. Coordinated forward error recovery for composite web services. In Proc. of 22nd Symposium on Reliable Distributed Systems, pages 167–176. IEEE Computer Society, 2003.
[18] Julie Vachon, Didier Buchs, Mathieu Buffo, Giovanna Di Marzo, Serugendo, Brian Randell, Sascha Romanovsky, Robert Stroud, and Jie Xu. Coala - a formal language for coordinated atomic actions. Technical report, third year report, ESPRIT Long Term Research Project 20072 on Design for Validation, 1998.
[19] J. Xu, A. B. Romanovsky, and B. Randell. Coordinated exception handling in distributed object systems: from model to system implementation. In Proceedings of 18th Inter. Conf. on Distributed Computing Systems, pages 12–21, 1998.
[20] Jie Xu, Brian Randell, Alexander B. Romanovsky, Cec´ılia M. F. Rubira, Robert J. Stroud, and Zhixue Wu. Fault tolerance in concurrent object-oriented software through coordinated error recovery. InProc. of the 25th International Symp. on Fault-Tolerant Computing, pages 499–509, 1995.
[21] Jie Xu, Brian Randell, Alexander B. Romanovsky, Robert J. Stroud, Avelino F. Zorzo, Ercum-ent Canver, and Friedrich W. von Henke. Rigorous developmErcum-ent of an embedded fault-tolerant system based on coordinated atomic actions. IEEE Trans. Computers, 51(2):164–179, 2002.
[22] Jie Xu, Alexander B. Romanovsky, and Brian Randell. Concurrent exception handling and resolution in distributed object systems. IEEE Trans. on Parallel and Distributed Systems, PDS-11(10):1019–1032, October 2000.
[23] Lingli Zhang, Chandra Krintz, and Priya Nagpurkar. Supporting exception handling for futures in java. In PPPJ, volume 272 of ACM International Conference Proceeding Series, pages 175–184. ACM, 2007.
Translation and Optimization for a Core
Calculus with Exceptions
Cristina David and Cristian Gherghina and Wei-Ngan Chin
Department of Computer Science, National University of Singapore
{cristina,cristian,chinwn}@comp.nus.edu.sg
Modern programming languages have many useful features to help the
construc-tion of software. Being meant for the development of applicaconstruc-tions, their main aim is
to offer a high degree of flexibility and ease of use to the programmer. Consequently,
they become complex and hard to analyse. For instance, one important feature is
exception handling. This feature is used to handle unusual conditions that can lead
to errors, unless remedial actions are suitably taken. However, exceptions may
in-duce non-local control flows that could make programs harder to analyse statically.
This worry is one reason why a number of past proposals (including our own work
[
5
]) on calculi to facilitate formal reasoning [
6
,
1
] have mostly ignored exceptions,
in the name of simplicity. Some recent proposals [
4
,
3
] have begun to consider a
core language with exceptions by adding both a
throw econstruct and a simplified
try e1catch(c v)e2construct from the Java language. However, this simplified feature
was not able to
succinctly
handle more advanced features, such as
try−finallynor
try−with−multiple−catches. Another proposal [
2
] directly adds these advanced features
in their core language, but this is done at the price of a more complex formalization.
Our proposal is to perform the analysis on an intermediate simplified core
cal-culus, avoiding the complexity of the source language, but without restricting the
flexibility expected by the programmers. The two crucial requirements for our
cal-culus are to be easy to analyse (
1
), and to be expressive enough as to allow the
translation of more complex language constructs into it (
2
). For achieving the first
goal (
1
), we endow our core calculus with a
unified view
of the control flow, which
spans two dimensions:
mines which parts of the program may be executed next, and the dynamic control
flow, where run-time values and inputs of the program are required to decide what
to execute next. This is achieved by translating the break, continue, return
con-structs (specific to the static control flow), and the try-catch and raise concon-structs
(specific to the dynamic control flow), into a unified control flow mechanism under
our calculus.
An unexpected benefit is that our core calculus with exceptions is
as small as
the
corresponding core calculus without exceptions. Designing analyses and
optimiza-tions for the core calculus is therefore much simpler than it would be for the source
language! With regard to the current work’s second goal (
2
), we prove the
ex-pressivity of the core calculus by providing a set of rewrite rules for translating a
medium-sized imperative source language into it.
We refer to our design as a
calculus
rather than a
language
since our intention
is to support a broader range of formal reasoning activities, including analysis,
lan-guage design, compilation, optimization and verification. The resulting core calculus
will essentially contain a core language and a set of rules (including translation) that
facilitate formal reasoning. Our goal is for a core calculus that is
syntactically
min-imal and expressively maxmin-imal
. We shall describe an application of our calculus,
namely optimization. In order to prove the soundness of the optimization rules, we
shall formalise the calculus by providing a big-step operational semantics.
References
[1]Sophia Drossopoulou and Susan Eisenbach. Java is Type Safe - Probably. InECOOP, pages 389–418, 1997.
[2]Sophia Drossopoulou and Tanya Valkevych. Java Exceptions Throw No Surprises. Technical report, March 2000.
[3]Jang-Wu Jo, Byeong-Mo Chang, Kwangkeun Yi, and Kwang-Moo Choe. An uncaught exception analysis for Java.Journal of Systems and Software, 72(1):59–69, 2004.
[4]Gerwin Klein and Tobias Nipkow. A machine-checked model for a Java-like language, virtual machine, and compiler.ACM Trans. Program. Lang. Syst., 28(4):619–695, 2006.
[5]H.H. Nguyen, C. David, S.C. Qin, and W.N. Chin. Automated Verification of Shape And Size Properties via Separation Logic. InVMCAI, Nice, France, January 2007.
[6]Tobias Nipkow and David von Oheimb. Javalight is Type-Safe - Definitely. InPOPL, pages 161–170,
Concern Based Approach to Generating SCR Requirement Specification: a
Case Study
*Ying Jin
1Jing Zhang
1Weiping Hao
1Pengfei Ma
1 1College of Computer Science and Technology, Jilin University, Changchun, P.R. China
[email protected]
*
This work is supported by China “863” High-tech Research and Development Project under Grant No. 2007AA01Z123.
Extended Abstract
SCR is a mature and widely used document driven requirement method, which emphasizes creating strict and complete formal requirement documents during software requirement analysis to serve the whole life circle[1]. However, due to the big gap between textual requirement description and formal requirement document, how to generate well defined, concise and strict formal requirement document from large scale and complex textual requirement statements has become a big challenge in application of SCR method.
In order to address this problem, a concern based approach to generating SCR requirement specification from prose description has been proposed[2]**, where concerns are used to bridge the gap between textual requirement definition and formal SCR specification. Concerns and their relationship are identified and specified, which will be used to guide identifying and specifying different constructs in SCR requirement documents.
A stepwise iterative process is proposed in this paper, which includes five steps: (1) concerns elicitation
Through reading and analyzing requirement statements carefully, behaviors, objects, goals, and properties can be elicited, some of which will be identified as concerns. This step can follow the idea of Theme/Doc method by utilizing nature language processor to identify different concerns from large scale and complex textual requirement statements [3]. Domain knowledge will be helpful in assisting concerns capturing.
(2) concerns & rough relation graph specification
With a set of concerns identified, these concerns will be specified. The formal definition of a concern includes a name, a piece of description, a set of related requirements, and a set of concepts it includes (concepts will be determined in step (3)). The dependency relationship among concerns will be recognized and specified as rough relation graph.
(3) concepts identification
For each concern and those requirements that it relates to, several concepts can be identified, which represent the key actions, objects or properties of that concern. Each concept can also be specified and added to the specification of the concern.
(4) variables definition and classification
For each concept and those requirements it resides, several variables will be defined and classified as monitored, controlled, input, output, term or mode. The classification of variables follows the ideas of SCR method.
(5) SCR requirement specification
In SCR approach, the system requirements are specified as a set of relations that the system must maintain. Three specifications are included in SCR requirement documents, they are system requirement specification(SRS), system design specification(SDS) and software requirement specification(SoRS). Detailed description of SCR requirement method can be found in [1].
a) SRS specification
b) SDS specification
SDS identifies and document input and output devices. For all input and output variables, we can trace back to those requirements where they were identified, and the relationship between input and output variables and the monitored and controlled variables.
c) SoRS specification
SoRS refines SRS by adding estimation of how to use input variables to calculate monitored values and how to derive output values from controlled values. Therefore, the correspondence between input variables and monitored variable, output variables and controlled variables will be specified.
d) Dealing with hardware malfunction and timing constraints
Finally, behaviors related to hardware malfunctions and timing constraints will be added.
The process defined above will be done iteratively until validation of intermediaries has been conformed. Concerns and their specification as well as concern relationship will be checked, negotiated and finally confirmed by different stakeholders together, and such checks as coverage, consistency and completeness of SCR specification can be conducted by tracing requirement statements, concepts, key variables and constructs in SCR specification.
To demonstrate and evaluate our method, we have applied it to a classical case – the Light Control System by specifying Hallway Section requirements[4]. It is indicated that our approach provides a guideline for bridging the gap between textual requirement definitions and formal SCR requirement documents via concerns, and facilitates applying aspect oriented approach to finding and solving conflicts in requirements.
Case studies have been given and discussed on SCR method[5], however, concerns have not been considered during deriving SCR specification from textual requirement definition.
Many works have been done on separation of concerns in requirement analysis and modeling [3,6,7]. All of these works focus on identifying and specifying concerns from either textual requirement definition or UML specification, especially AORE is for identifying and composing crosscutting concerns. Concerns are used to modularize requirements, not for generating formal requirement documents.
Concept-based approach for requirement analysis and modeling is proposed in [8], which utilizes formal concept analysis for finding or delivering class candidates from a given use case description.
Our approach is inspired by [3] for concern identification in prose requirement statements and [8] for using concepts to model requirements, however, our approach focuses on producing formal requirement specification from textual requirement definition with concerns and concepts as the intermediaries.
Lack of tool support will make it hard to apply our approach to a big practical project. Therefore, a prototype for specification of concerns and their relationship is under development in our lab. In the future, we would like to use formal concept analysis to help validation of concerns specification and requirement specification, conduct more case studies to real systems by utilizing supporting tool so that some quantitative results will be generated on the benefits of our approach.
References
[1] C. Heitmeyer. Formal Methods for Specifying, Validating, and Verifying Requirements. J. UCS 13(5): 607-618 (2007) [2] Ying Jin, Jing Zhang, Weiping Hao, Pengfei Ma. Concern Based Approach to Generating SCR Requirement Specification: a
Case Study, accepted by CSIE2009, March 31 - April 2, 2009, Los Angeles/Anaheim, USA.
[3] Baniassad, Clarke, Theme: An Approach for Aspect-oriented Analysis and Design[C]//Proceedings of the 26th Int’l Conf. on Software Engineering, Edinburgh, Scotland. 2004: 158-167.
[4] The light control case study: Problem description. Journal of Universal Computer Science, Special Issue on Requirements Engineering ,Vol. 6, 2000.
[5] C. Heitmeyer, R. Bharadwaj. Applying the SCR Requirements Method to the Light Control Case Study. Journal of Universal Computer Science (JUCS), August 2000.
[6] S. M Sutton Jr. Early-Stage Concern Modeling. Workshop on Early Aspects: Aspect-Oriented Requirements Engineering and Architecture Design, 1st International Conference on Aspect-Oriented Software Development, Enschede, The Netherlands, April, 2002.
[7] E. L. A. Baniassad, P. Clements, J. Araujo, A. Moreira, A. Rashid, and B. Tekinerdogan (2006) Discovering Early Aspects. IEEE Software. Volume 23, Pages 61-69.
User-oriented Preparative Treatments for
Requirements Engineering
Fei He
1Yoshiaki Fukazawa
2Department of Computer Science and Engineering Waseda University,
Okubo 3-4-1, Shinjuku-ku, Tokyo, Japan
Abstract
In order to resolve the classical problems (the major difficulties are the user needs and for developers to understand those needs) of requirements engineering, we propose a 3-phase user-oriented preparative treatment to generate clear user requirements and offer those user requirements as high quality input resources for the later generation of system requirements: phase 1, to build up users’ user information reserves. Only when we put an application system in the background of users' whole systematic and informationalized reserve assets, rather than treat it as an independent or solitary entity, can we fully understand the assigned roles and positions of the application system, and only in this way can we correctly anticipate the way of evolutions of the application system and realize the essence of its requirements; phase 2, to generate user requirements which are descriptions of states and problems of certain business application, and are independent to system requirements which focus on solutions for system implementation; phase 3, to generate system requirements by using user requirements, and build up the linkage between user requirements and system requirements.
Keywords: user-oriented preparative treatment, user information reserve, user requirements.